Navigation: <-- Underfitting and Overfitting | Part Index | Main Index | Hyperparameter Optimization -->
Regularized Regression
Requires: Linear Regression · Gradient Descent
Motivation: A model that is too flexible memorizes noise instead of learning the pattern, as we just introduced in 🖝 Underfitting and Overfitting. Regularization is one approach to push back against overfitting: rather than changing the model family, it adds a penalty to the loss, making large coefficients costly and nudging the optimizer toward simpler solutions.
In this nugget you will learn two regularization strategies for linear regression. L2 (Ridge) shrinks all weights without eliminating any. L1 (Lasso) performs implicit feature selection by driving some weights to exactly zero.
Table of Contents
- When Minimizing Loss Isn't Enough
- L2 Regularization (Ridge): Shrinkage
- L1 Regularization (Lasso): Sparsity
- Summary
When Minimizing Loss Isn't Enough
The MSE loss has no opinion about weight size, only about prediction error. Nothing prevents the optimizer from assigning large, unstable weights that chase noise in the training data. This is the overfitting pattern from 🖝 Underfitting and Overfitting, now visible in the values of weight parameters themselves.
One direct remedy is to add a penalty term to the MSE loss we introduced in 🖝 Linear Regression. Instead of minimizing MSE alone, the model now minimizes:
The regularization strength \(\lambda \geq 0\) controls the trade-off. A larger \(\lambda\) forces smaller weights, accepting higher training error in exchange for a simpler model. Setting \(\lambda = 0\) recovers plain linear regression.
The two main regularization strategies differ only in how the penalty term is defined.
L2 Regularization (Ridge): Shrinkage
L2 regularization penalizes the sum of squared weight values:
The sum runs over the \(k\) feature weights \(w_1, \ldots, w_k\). This excludes the intercept \(w_0\), which is not penalized by convention.
Squaring penalizes large coefficients far more than small ones. As a weight approaches zero the squared penalty becomes negligible, so the optimizer has little incentive to push any coefficient all the way to zero. Instead, all weights shrink toward zero but remain nonzero. This is called weight shrinkage.
L2-regularized regression, also known as Ridge regression, usually handles correlated predictors as follows: When two features carry similar information, Ridge distributes weight across both. This tends to produce stable estimates.
In practice, Python scikit-learn provides a ready-made model for L2-penalized linear regression (Ridge). It uses the parameter name alpha for what this nugget calls \(\lambda\):
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0) # alpha is sklearn's name for λ
model.fit(X_train, y_train)
L1 Regularization (Lasso): Sparsity
L1 regularization penalizes the sum of absolute weight values:
In contrast to L2 regularization, L1 regularization tends to zero out some weights entirely. Let's take a look at geometry to build some intuition why this is the case:
- The L2 penalty has a smooth shape: a down-hill optimizer like 🖝 Gradient Descent can usually improve a weight slightly without hitting a corner.
- The L1 penalty has a diamond shape: its corners sit exactly at coordinates where some weights are zero. Because of their sharpness, corners are often the optimum for the full loss function, too.
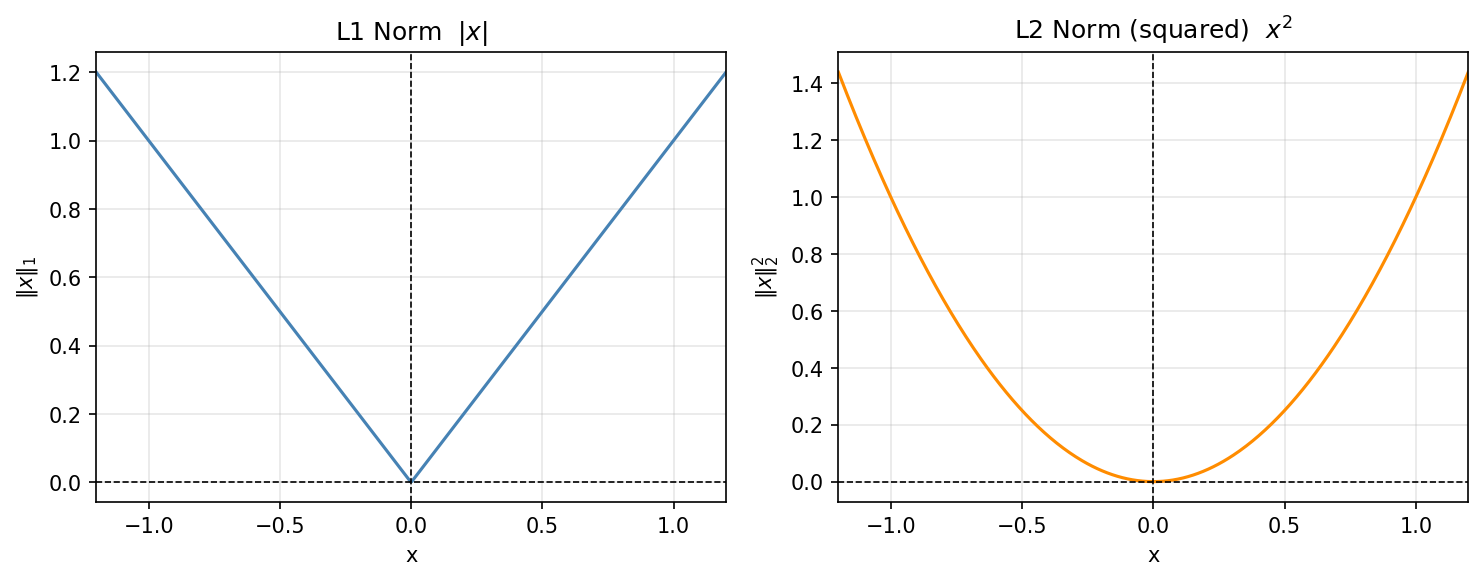
L1 therefore performs implicit feature selection: predictors whose weights reach exactly zero are dropped from the model, and the solution is sparse. Unlike Ridge, which shrinks all coefficients proportionally, Lasso tends to zero one correlated predictor while retaining another. This makes it well-suited when you suspect only a few features are genuinely informative.
In scikit-learn, L1-penalized linear regression is called Lasso:
from sklearn.linear_model import Lasso
model = Lasso(alpha=0.1) # alpha is sklearn's name for λ
model.fit(X_train, y_train)
Choosing \(\lambda\) for either method is the central question in the next nugget on 🖝 Hyperparameter Optimization.
Let's close this nugget with an observation and a discussion anchor:
Callback: analogy in form, not in function: You have already seen absolute values in regression, in the LAD loss from the 🖝 Linear Regression nugget. There, \(|y_j - h_\mathbf{w}(\mathbf{x}_j)|\) measured the size of a residual in the loss, making the fit robust to outliers. Here, \(|w_j|\) measures the size of a weight in a penalty term, pushing coefficients toward zero. Same mathematical operation, two completely different purposes.
Discussion: You are predicting well-being from a dataset with 30 candidate features. You suspect only five or six are genuinely informative, and several of those correlate with each other. Would you start with Lasso or Ridge, and why? What would you look for in the results to confirm your choice?
Summary
- Unregularized linear regression can overfit by assigning large, unstable weights, especially with many or correlated features.
- Adding a penalty term \(\lambda \cdot \text{Penalty}(\mathbf{w})\) forces the optimizer to balance prediction error against weight size. The strength \(\lambda\) controls this trade-off.
- L2 (Ridge) penalizes squared weight values and shrinks all coefficients toward zero without zeroing them, distributing weight evenly across correlated predictors.
- L1 (Lasso) penalizes absolute weight values and drives some coefficients to exactly zero, performing implicit feature selection.
As always: Happy learning, happy life! 🫶
Navigation: <-- Underfitting and Overfitting | Part Index | Main Index | Hyperparameter Optimization -->
Script v1.4 (2026-06-10) · FGN